HiCache 系统设计与优化#
本文档全面概述了 SGLang HiCache,涵盖了其系统架构、工作流程和关键组件。它还详细介绍了配置参数、优化技术以及与各种 L3 存储后端的集成,旨在为用户和开发人员理解和调优 HiCache 以实现高效的 LLM 推理提供完整参考。
为什么需要 HiCache?它是什么?#
在大语言模型推理中,Prefill(预填充)阶段往往非常耗时:输入序列需要先转换为 Key-Value 缓存(KV cache)以供后续解码使用。当多个请求共享相同的前缀时,该前缀的 KV 缓存是完全相同的。通过缓存并复用这些共享的 KV 缓存,可以避免重复计算。为了解决这一问题,SGLang 引入了 RadixAttention(利用空闲 GPU 显存缓存和复用前缀 KV 缓存)以及 HiCache(将这一理念扩展到主机内存和分布式存储)。
受现代 CPU 经典三级缓存设计的启发,HiCache 将 GPU 显存组织为 L1,主机内存组织为 L2,分布式存储组织为 L3。这种层次结构使 HiCache 能够充分利用 GPU 和 CPU 的“空闲”存储空间,同时集成了 Mooncake、3FS、NIXL 和 AIBrix KVCache 等分布式缓存系统,用于全局 KV 缓存的存储和调度。因此,HiCache 在保持强劲读取性能的同时,显著扩展了 KV 缓存容量——特别是在多轮问答和长文本推理等 KV 缓存复用频繁的场景中。有关详细的基准测试结果,请参阅此博客。
系统设计#
整体架构#
在许多现代 CPU 架构中,容量小但速度快的 L1 和 L2 缓存是每个核心私有的,以便快速访问最热的数据,而容量更大的 L3 缓存则由所有核心共享,从而显著减少缓存内的冗余。类似地,在 HiCache 中,L1 和 L2 KV 缓存对每个推理实例是私有的,而 L3 KV 缓存则由集群内的所有推理实例共享。
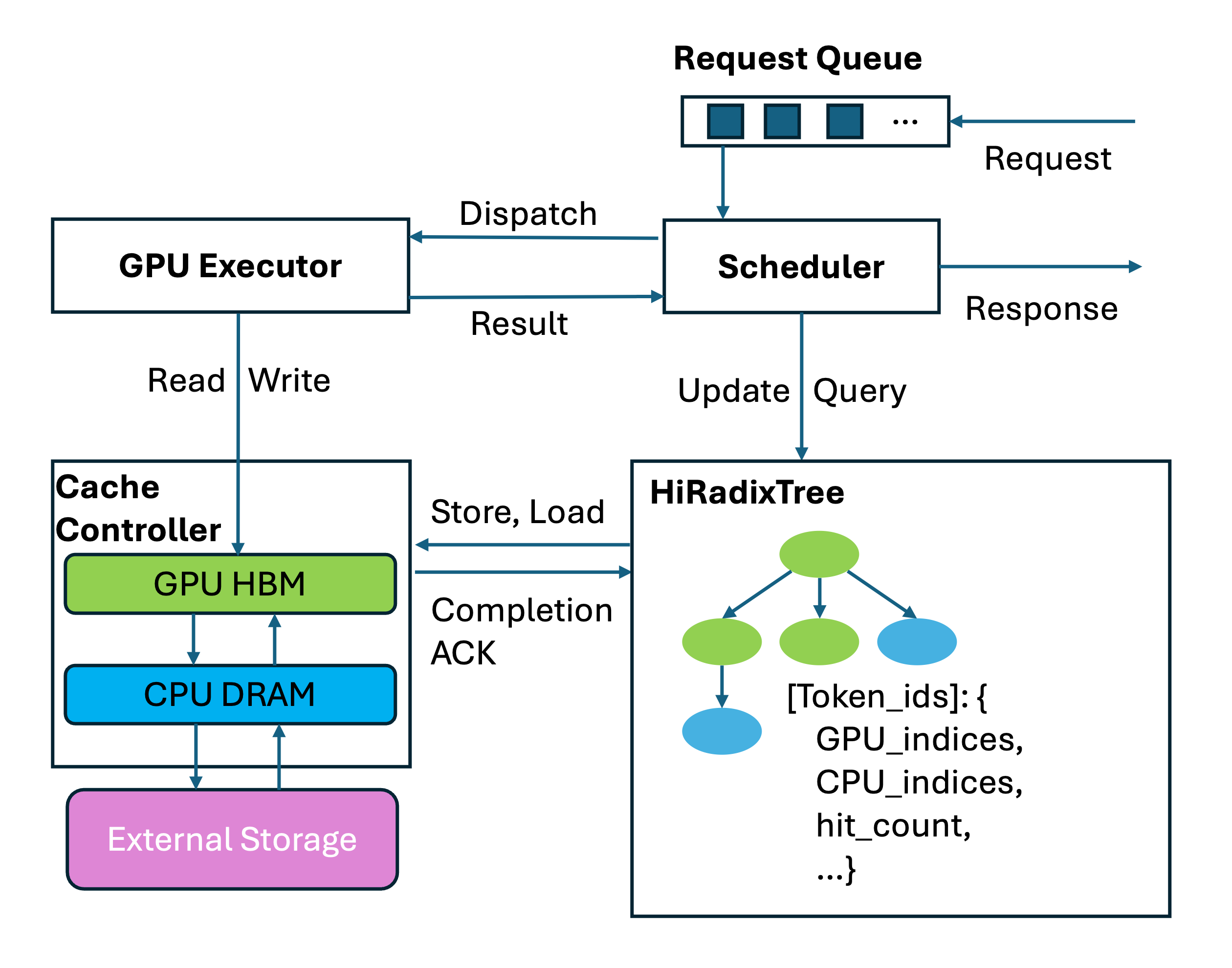
HiRadixTree:HiCache 中的元数据组织#
在 KV 缓存数据组织方面,HiCache 基于 RadixAttention 中引入的 RadixTree 结构,提出了 HiRadixTree。在 RadixAttention 中,RadixTree 的每个节点对应 GPU 显存中一段连续 Token 的 KV 缓存。从根节点到叶节点的路径代表请求的前缀,多个请求之间的共享前缀可以复用相同的节点,从而避免重复存储。
HiRadixTree 扩展了这一理念:每个节点对应一段连续 Token 的 KV 缓存,并记录该 KV 缓存储存在何处——无论是本地 GPU 显存、CPU 内存、L3 存储,还是其中的多个层级。如果是本地存储,HiRadixTree 会维护精确的元数据,包括具体的存储地址。然而,为了减少开销,HiRadixTree 不会存储或持续同步 L3 KV 缓存的元数据。相反,在访问 L3 数据时,它会实时查询后端以获取必要的元数据,例如数据是否存在以及驻留在哪台服务器和位置。
整体工作流#
HiCache 的工作流程主要涉及三个关键操作:本地匹配 (local match)、预取 (prefetch) 和 写回 (write-back)。当系统接收到新请求时,首先在本地 L1 和 L2 缓存中搜索匹配的 KV 缓存。对于本地未找到的部分,它会尝试从 L3 预取。预取完成后,所有需要的 KV 缓存都会加载到 GPU 中进行计算。一旦 Prefill 计算完成,系统会考虑将新生成的数据存储到 L2 或 L3 中。
本地匹配#
本地匹配是 HiCache 工作流的第一步,传入的请求 Token 会与 HiRadixTree 进行匹配,以定位本地存储层级(L1 GPU 显存和 L2 主机内存)中缓存的 KV 数据。
匹配算法从根节点开始遍历 HiRadixTree,沿着与 Token 序列前缀匹配的子节点进行。在每个节点,传入的 Token 序列会与节点存储的 Token 序列进行比较。当 page_size > 1 时,匹配以页面(page)粒度执行,以优化内存访问模式。如果匹配在节点存储的序列内部终止,节点会自动分裂以创建一个精确的边界,从而提高未来匹配的效率。
该算法返回请求的一个连续前缀,其中第一部分位于 L1,后一部分位于 L2。
由于该过程仅需遍历本地 HiRadixTree,不涉及任何实际的数据拷贝,因此本地匹配速度极快。
从 L3 预取#
数据预取是 HiCache 的核心优化技术之一,旨在主动将 KV 缓存从 L3 存储加载到本地 L2 内存,从而降低后续操作期间的访问延迟。
预取触发条件:本地匹配后,对于在 L1 或 L2 中未找到的部分,系统会查询 L3 以获取后续连续匹配 KV 缓存的元数据。如果 L3 中命中缓存的长度超过阈值(默认:256 Token,可配置),则触发预取操作。
预取策略:HiCache 提供了三种不同的预取终止策略,以满足不同场景的需求:
best_effort:当 GPU 可以执行 Prefill 计算时立即终止,无需等待,适用于对延迟极其敏感的场景。
wait_complete:必须等待所有预取操作完成,适用于需要高缓存命中率的场景。
timeout:在指定时间后或完成时终止,平衡延迟和缓存命中率的需求。
预取停止后,已获取的数据将与本地数据一起用于 Prefill 计算。
对于 timeout 策略,HiCache 引入了两个配置参数,以支持对预取超时条件的精细控制:
prefetch_timeout_base:基础超时时间,代表与 Token 数量无关的开销(如调度和同步)。prefetch_timeout_per_ki_token:每千个 Token 的增量超时时间。
超时时间计算公式为:
timeout = prefetch_timeout_base + prefetch_timeout_per_ki_token * num_token_to_fetch / 1024
数据写回#
写回机制负责将频繁访问的 KV 缓存从 L1 移动到 L2 和 L3,从而实现更大容量和更长期的存储,以及跨实例的缓存共享。
可配置的写回策略:HiCache 支持三种写回策略:
write_through:每次访问都立即写回到下一层级。在带宽充足时,该策略提供最强的缓存收益。
write_through_selective:仅在访问频率超过阈值后才写回数据。该策略仅备份热数据,减少 I/O 开销。
write_back:仅当数据从上一层级逐出时才写回到下一层级。该策略缓解了存储压力,适用于存储容量有限但必须最大化内存利用率的场景。
跨实例共享:当数据从 L2 写回到 L3 时,仅传输 L3 中尚不存在的数据。存储在 L3 中的 KV 缓存随后可以由集群中的所有 SGLang 实例共享(取决于 L3 后端实现),从而在相同的内存预算内显著提高缓存命中率。
多 Rank 同步#
在多 GPU 并行计算(如张量并行 TP)期间,HiCache 必须确保不同 Rank 之间状态一致。因此,关键计算步骤需要使用 all_reduce 进行状态同步。
例如,在预取期间,使用 all_reduce(op=min) 确保所有 Rank 获得相同的 L3 命中数量,防止对是否达到预取阈值的判断不一致。同样,在预取完成或终止后,再次需要 all_reduce(op=min) 以保证各 Rank 之间对成功检索到的 KV 缓存前缀长度达成共识。
数据传输优化#
零拷贝数据传输:预取和写回都涉及大量数据移动。最小化数据拷贝次数可以显著提高系统性能。HiCache 支持在将数据从 L2 内存传输到 L3 后端时直接传递内存地址和大小。
“面向批次”的数据组织:数据读写的粒度对性能有重大影响。为了解决这个问题,HiCache L3 以 pages 为粒度存储和传输 KV 缓存数据,并支持除现有 layer first 方案之外的不同数据布局,包括 page first 和 page first direct。在 page first 和 page first direct 布局下,属于同一页面的所有 KV 缓存数据都放置在连续内存中,允许通过零拷贝传输将其作为一个对象传递给 L3。
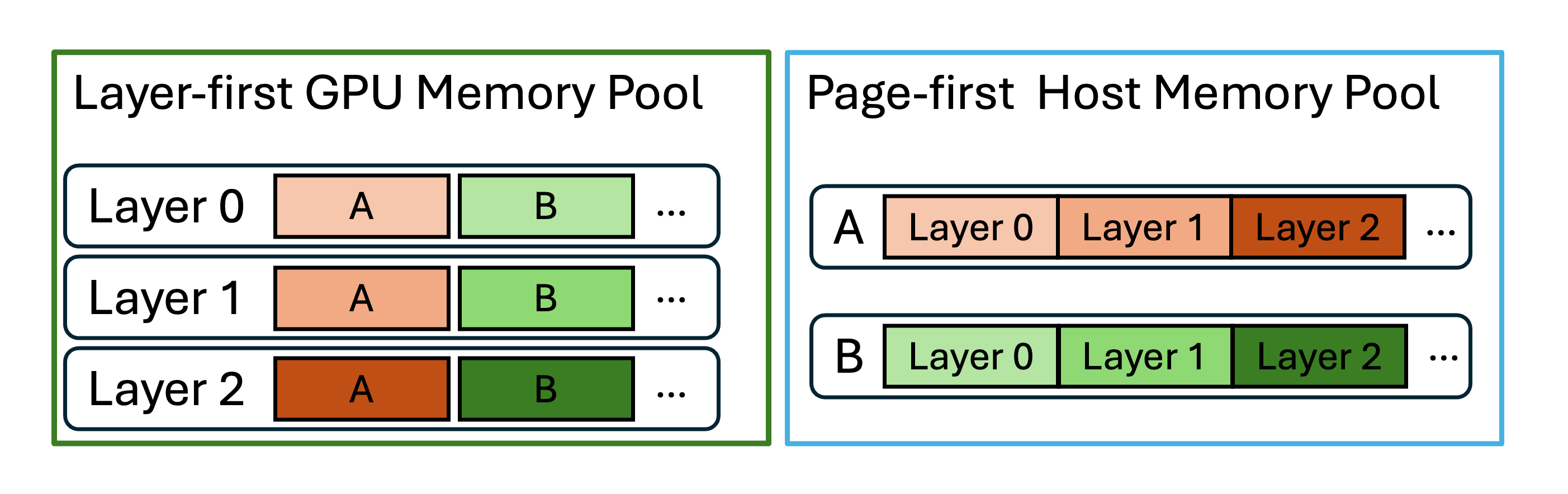
然而,由于 GPU KV 计算自然地按层(layer)进行,GPU 本质上以 layer first 布局运行。当将 page first 数据从 L2 传输到 GPU 时,数据必须以“每层一个 Token”的粒度进行传输。page first direct 布局通过将页面内给定层的所有 Token 分组在一起缓解了此问题,从而允许从 L2 到 GPU 的传输在“页面-层”级别进行聚合。
CPU 到 GPU 传输优化:在 HiCache 中,将数据从 CPU 内存移动到 GPU 与从 L3 预取数据到 L2 同样关键。HiCache 为此过程采用了多种优化:
计算-传输重叠:在 Prefill 阶段,当将数据从 CPU 传输到 GPU 时,HiCache 通过在计算第 N 层时并发加载第 N+1 层的 KV 缓存来实现层级重叠。这有效地隐藏了数据传输延迟。
GPU 辅助 I/O Kernel:在
cudaMemcpyAsync之上,HiCache 实现了一组专门针对 CPU 和 GPU 之间 KV 缓存传输优化的 GPU 辅助 I/O Kernel。与基准方法相比,这些 Kernel 实现了高达 3 倍的传输速度。
MLA 写回优化:对于多 TP 下的 MHA(多头注意力)模型,每个 Rank 持有一个 Token KV 数据的 1/tp_size。相比之下,对于 MLA(多层注意力)模型,所有 Rank 为每个 Token 持有完整且相同的 KV 数据。HiCache 为 MLA 包含了一项专用优化:仅由一个 Rank 发起写回操作,确保数据不会在 Rank 之间冗余存储。
与 PD 分离部署模式的集成#
SGLang 通过 Mooncake TransferEngine 支持 PD(Prefill-Decode)分离部署模式(详情请参阅此文档)。在 PD 分离部署模式下,可以在 Prefill 节点和 Decode 节点上同时启用 HiCache 以优化 Prefill 性能。如果在 Decode 节点上启用,Decode 输出也将写回到 L3。
统一接口与丰富的 L3 存储后端#
HiCache 将 L3 后端的所有读、写和查询操作封装在 class HiCacheStorage(ABC) 中,暴露出一组简单且一致的接口。这种设计支持广泛的 L3 存储后端,并允许用户选择最适合其特定用例的后端。
Mooncake:Mooncake 是一个高性能的 LLM 推理缓存系统,利用 RDMA 和多网卡资源实现零拷贝、极速数据传输。在此处尝试 Mooncake。
DeepSeek 3FS (HF3FS):HF3FS 是一个 Kubernetes 原生分布式存储解决方案,采用基于 Operator 的部署。在此处尝试 HF3FS。
NIXL:NIXL 提供了一个统一 API,用于访问各种存储插件,包括但不限于 DeepSeek 的 3FS、GPU Direct Storage (GDS) 和兼容 Amazon S3 的对象存储。在此处尝试 NIXL。
AIBrix KVCache:AIBrix KVCache 是一个生产级的 KVCache 卸载框架,支持高效的内存分层和低开销的跨引擎复用。在此处尝试 AIBrix KVCache。
HiCacheFile:一个用于演示目的的简单基于文件的存储后端。
特别地,LMCache 作为一个面向企业级 LLM 推理的高效 KV 缓存层,提供了 HiCache 的替代方案。在此处尝试 LMCache。